diff --git a/dennis/.gitignore b/dennis/.gitignore
index a5082c9..f834aec 100644
--- a/dennis/.gitignore
+++ b/dennis/.gitignore
@@ -1,6 +1,5 @@
bin/
dist/
lib/
-test/
__pycache__/
pyvenv.cfg
diff --git a/dennis/requirements.txt b/dennis/requirements.txt
index 97dc7cd..3494b8e 100644
--- a/dennis/requirements.txt
+++ b/dennis/requirements.txt
@@ -1,2 +1,3 @@
fastapi
uvicorn
+markdown
diff --git a/dennis/test/blog/000000000-swim.md b/dennis/test/blog/000000000-swim.md
new file mode 100644
index 0000000..e4b9e9c
--- /dev/null
+++ b/dennis/test/blog/000000000-swim.md
@@ -0,0 +1,140 @@
+Content_Type: blog
+Title: Hume
+Date: 2022 2 7
+
+
+ April 22, 1958
+ 57 Perry Street
+ New York City
+
+Dear Hume,
+
+You ask advice: ah, what a very human and very dangerous thing to do! For to give advice
+to a man who asks what to do with his life implies something very close to egomania. To
+presume to point a man to the right and ultimate goal—to point with a trembling
+finger in the RIGHT direction is something only a fool would take upon himself.
+
+I am not a fool, but I respect your sincerity in asking my
+advice. I ask you though, in listening to what I say, to remember that all advice can
+only be a product of the man who gives it. What is truth to one may be a disaster to
+another. I do not see life through your eyes, nor you through mine. If I were to attempt
+to give you
+*specific* advice, it would be too much like the blind leading the blind.
+
+ "To be, or not to be: that is the question: Whether 'tis nobler in the mind to
+ suffer the slings and arrows of outrageous fortune, or to take arms against a sea of
+ troubles..."
+
+ (Shakespeare)
+
+And indeed, that IS the question: whether to float with the tide, or to swim for a goal.
+It is a choice we must all make consciously or unconsciously at one time in our lives.
+So few people understand this! Think of any decision you've ever made which had a
+bearing on your future: I may be wrong, but I don't see how it could have been anything
+but a choice however indirect—between the two things I've mentioned: the floating
+or the swimming.
+
+But why not float if you have no goal? That is another question.
+It is unquestionably better to enjoy the floating than to swim in uncertainty. So how
+does a man find a goal? Not a castle in the stars, but a real and tangible thing. How
+can a man be sure he's not after the "big rock candy mountain," the enticing sugar-candy
+goal that has little taste and no substance?
+
+The answer—and, in a sense, the tragedy of life—is
+that we seek to understand the goal and not the man. We set up a goal which demands of
+us certain things: and we do these things. We adjust to the demands of a concept which
+CANNOT be valid. When you were young, let us say that you wanted to be a fireman. I feel
+reasonably safe in saying that you no longer want to be a fireman. Why? Because your
+perspective has changed. It's not the fireman who has changed, but you. Every man is the
+sum total of his reactions to experience. As your experiences differ and multiply, you
+become a different man, and hence your perspective changes. This goes on and on. Every
+reaction is a learning process; every significant experience alters your perspective.
+
+So it would seem foolish, would it not, to adjust our lives to
+the demands of a goal we see from a different angle every day? How could we ever hope to
+accomplish anything other than galloping neurosis?
+
+The answer, then, must not deal with goals at all, or not with
+tangible goals, anyway. It would take reams of paper to develop this subject to
+fulfillment. God only knows how many books have been written on "the meaning of man" and
+that sort of thing, and god only knows how many people have pondered the subject. (I use
+the term "god only knows" purely as an expression.) There's very little sense in my
+trying to give it up to you in the proverbial nutshell, because I'm the first to admit
+my absolute lack of qualifications for reducing the meaning of life to one or two
+paragraphs.
+
+I'm going to steer clear of the word "existentialism," but you
+might keep it in mind as a key of sorts. You might also try something called
+Being and Nothingness by Jean-Paul Sartre, and another little thing called
+Existentialism: From Dostoyevsky to Sartre. These are merely suggestions. If
+you're genuinely statisfied with what you are and what you're doing, then give those
+books a wide berth. (Let sleeping dogs lie.) But back to the answer. As I said, to put
+our faith in tangible goals would seem to be, at best, unwise. So we do not strive to be
+firemen, we do not strive to be bankers, nor policemen, nor doctors. WE STRIVE TO BE
+OURSELVES.
+
+But don't misunderstand me. I don't mean that we can't BE
+firemen, bankers, or doctors—but that we must make the goal conform to the
+individual, rather than make the individual conform to the goal. In every man, heredity
+and environment have combined to produce a creature of certain abilities and
+desires—including a deeply ingrained need to function in such a way that his life
+will be MEANINGFUL. A man has to BE something; he has to matter.
+
+As I see it then, the formula runs something like this: a man
+must choose a path which will let his ABILITIES function at maximum efficiency toward
+the gratification of his DESIRES. In doing this, he is fulfilling a need (giving himself
+identity by functioning in a set pattern toward a set goal) he avoids frustrating his
+potential (choosing a path which puts no limit on his self-development), and he avoids
+the terror of seeing his goal wilt or lose its charm as he draws closer to it (rather
+than bending himself to meet the demands of that which he seeks, he has bent his goal to
+conform to his own abilities and desires).
+
+In short, he has not dedicated his life to reaching a
+pre-defined goal, but he has rather chosen a way of like he KNOWS he will enjoy. The
+goal is absolutely secondary: it is the
+functioning toward the goal which is important. And it seems almost ridiculous to
+say that a man MUST function in a pattern of his own choosing; for to let another man
+define your own goals is to give up one of the most meaningful aspects of life—the
+definitive act of will which makes a man an individual.
+
+Let's assume that you think you have a choice of eight paths to
+follow (all pre-defined paths, of course). And let's assume that you can't see any real
+purpose in any of the eight. Then—and here is the essence of all I've
+said—you MUST FIND A NINTH PATH.
+
+Naturally, it isn't as easy as it sounds. you've lived a
+relatively narrow life, a vertical rather than a horizontal existence. So it isn't any
+too difficult to understand why you seem to feel the way you do. But a man who
+procrastinates in his CHOOSING will inevitably have his choice made for him by
+circumstance.
+
+So if you now number yourself among the disenchanted, then you
+have no choice but to accept things as they are, or to seriously seek something else.
+But beware of looking for
+goals: look for a way of life. Decide how you want to live and then see what you
+can do to make a living WITHIN that way of life. But you say, "I don't know where to
+look; I don't know what to look for."
+
+And there's the crux. Is it worth giving up what I have to look
+for something better? I don't know—is it? Who can make that decision but you? But
+even by DECIDING TO LOOK, you go a long way toward making the choice.
+
+If I don't call this to a halt, I'm going to find myself writing
+a book. I hope it's not as confusing as it looks at first glance. Keep in mind, of
+course, that this is MY WAY of looking at things. I happen to think that it's pretty
+generally applicable, but you may not. Each of us has to create our own credo—this
+merely happens to be mine.
+
+If any part of it doesn't seem to make sense, by all means call
+it to my attention. I'm not trying to send you out "on the road" in search of Valhalla,
+but merely pointing out that it is not necessary to accept the choices handed down to
+you by life as you know it. There is more to it than that—no one HAS to do
+something he doesn't want to do for the rest of his life. But then again, if that's what
+you wind up doing, by all means convince yourself that you HAD to do it. You'll have
+lots of company.
+
+And that's it for now. Until I hear from you again, I remain,
+
+ your friend...
+ Hunter
+
diff --git a/dennis/test/blog/20220506-change.md b/dennis/test/blog/20220506-change.md
new file mode 100644
index 0000000..cf42db6
--- /dev/null
+++ b/dennis/test/blog/20220506-change.md
@@ -0,0 +1,50 @@
+Content_Type: blog
+Title: Change
+Date: 2022 5 6
+
+
+ "Life should not be a journey to the grave with the intention of arriving safely in
+ a pretty and well preserved body, but rather to skid in broadside in a cloud of
+ smoke, thoroughly used up, totally worn out, and loudly proclaiming "Wow! What a
+ Ride!"
+
+ (Hunter S.Thompson)
+
+There comes a time in one's life, perhaps multiple, when there
+is an unquestionable need for change. Maybe you're not sure how, why, or where it came
+from, or where even it is you're headed, or how to get there, but here you are taking
+your first steps toward a new life. A journey into the unknown. I've just set out on one
+of these journeys, and even as I sit here typing this now I can't help but feel a little
+bit nervous, but even more excited. I have absolutely no idea where I'm headed to be
+quite honest. But I know where I've been.
+
+Growing up I would always be taking things apart, I HAD to see
+what was inside. What makes this thing, a thing. What makes it tick? Can it tick faster?
+For no particular reason I just had to know every little detail about what made the
+thing the thing that it was and why it did what it did. It's a gift and a curse of
+sorts. Quickly this led to taking apart things of increasing complexity, our home
+computer for instance. Luckily I was able to get it put back together before my parents
+got home because it was made clear that this was not allowed, and the CPU didn't seem to
+mind the sudden absence of thermal compound either. I must have been around 7 or 8 years
+old at that time, and it still puzzles me just what is going on inside there.
+
+I have a better idea now, naturally I had to figure out just
+what all those pieces were, what they did, and how they did it. What if I replaced some
+of these parts with other parts? As I honed my web searching skills to try to answer the
+seemingly endless hows and whys I ended up building myself a little hotrod computer and
+then raced it against other peoples' computers because why not, right? And I actually
+won! It was an overclocking contest called the winter suicides, a kind of computer drag
+race. Highest CPU clock speed wins, you have to boot into Windows XP, open CPU-Z, and
+take a screenshot. If it crashes immediately after that (and it did) it still counts. I
+got some pretty weird looks from my father as I stuck my computer outside in the snow
+but that was a small price to pay for the grand prize which was a RAM kit (2GB of DDR400
+I believe) and RAM cooler.
+
+After getting comfortable with hardware I started to study the
+software side of things, I tried teaching myself C++ (and didn't get very far), I did
+teach myself HTML and CSS, some JavaScript, and started playing around with Linux. It
+took until only a year or two ago to finally be completely on Linux full time (gaming
+holding me back), I even have a Linux phone now (Pinephone Pro). At this point I reached
+high school and my attention moved from computers to cars.
+
+To be continued...
diff --git a/dennis/test/blog/20220520-nvidia.md b/dennis/test/blog/20220520-nvidia.md
new file mode 100644
index 0000000..43b826e
--- /dev/null
+++ b/dennis/test/blog/20220520-nvidia.md
@@ -0,0 +1,12 @@
+Content_Type: blog
+Title: It's about time, NVIDIA
+Date: 2022 5 20
+
+It's about time... NVIDIA has finally released and is starting to
+support Open-source software with their new modules released recently for the Linux
+kernel. NVIDIA historically has been seemingly against Linux/OSS for whatever reason.
+This is a huge step forward both for end users and NVIDIA.
+
+
+ NVIDIA open-gpu-kernel-modules on github.
+
diff --git a/dennis/test/blog/20220602-back.md b/dennis/test/blog/20220602-back.md
new file mode 100644
index 0000000..ad5dfe6
--- /dev/null
+++ b/dennis/test/blog/20220602-back.md
@@ -0,0 +1,39 @@
+Content_Type: blog
+Title: Back to School
+Date: 2022 6 2
+
+### Where the hell have I been!?
+
+Looking back at the past 5 weeks, it's impressive the amount of new things that have
+been shoved in my face. A list I'll try to make contains:
+
+* [Python](https://www.python.org)
+* [Pandas](https://pandas.pydata.org)
+* [Matplotlib](https://matplotlib.org)
+* [Seaborn](https://seaborn.pydata.org)
+* [Statsmodels](https://www.statsmodels.org)
+* [Scikit-Learn](https://scikit-learn.org)
+* [Beautiful Soup](https://www.crummy.com/software/BeautifulSoup)
+* [Selenium](https://www.selenium.dev)
+* [PRAW](https://github.com/praw-dev/praw)
+* Plus the math and background to go with it all!
+
+It doesn't seem like much at the time except chaos, but then about a week later it
+finally sets in. After tomorrow we'll be halfway through the course and while I guess
+you could say that it's half over, or that it signifies progress, I feel it's more like
+being halfway up Mount Everest and looking—trying to squint through the clouds and
+make out what looks like the peak. I don't see a peak and maybe it's because I'm
+nearsighted but I can also tell you that if were to look down then I can't see where
+I've started either!
+
+It's been quite a ride and I hope to see it to the end. I don't have time to even think
+about it further. It's where I perform my best though, on my heels. Probably by
+design...
+
+### After?
+
+I would like to use these skills to expand on some of the class projects I've worked on
+and I have some other ideas using language processing I think would be fun to play with.
+I think it would be fun to create an internet chat bot, we'll start with text but if
+speech recognition is practical then I may add and play with that too. I would also like
+to make some sort of "Propaganda Detector"
diff --git a/dennis/test/blog/20220701-progress.md b/dennis/test/blog/20220701-progress.md
new file mode 100644
index 0000000..3d2d91f
--- /dev/null
+++ b/dennis/test/blog/20220701-progress.md
@@ -0,0 +1,85 @@
+Content_Type: blog
+Title: It's a post about nothing!
+Date: 2022 7 1
+
+The progress update
+
+
+  +
+
+
+### Bots
+
+After finding a number of ways not to begin the project formerly known as my capstone,
+I've finally settled on a
+[dataset](https://www.kaggle.com/datasets/bwandowando/ukraine-russian-crisis-twitter-dataset-1-2-m-rows). The project is about detecting bots, starting with twitter. I've
+[studied](https://old.doordesk.net/projects/bots/docs/debot.pdf) a
+[few](https://old.doordesk.net/projects/bots/docs/botwalk.pdf)
+[different](https://old.doordesk.net/projects/bots/docs/smu.pdf)
+[methods](https://old.doordesk.net/projects/bots/docs/div.pdf) of bot detection and particularly like the
+[DeBot](https://old.doordesk.net/projects/bots/docs/debot.pdf) and
+[BotWalk](https://old.doordesk.net/projects/bots/docs/botwalk.pdf) methods and think I will try to mimic them,
+in that order.
+
+Long story short, DeBot uses a fancy method of time correlation to group accounts
+together based on their posting habits. By identifying accounts that all have identical
+posting habits that are beyond what a human could do by coincidence, this is a great
+first step to identifying an inital group of seed bots. This can then be expanded by
+using BotWalk's method of checking all the followers of the bot accounts and comparing
+anomalous behavior to separate humans from non-humans. Rinse and repeat. I'll begin this
+on twitter but hope to make it platform independent.
+
+### The Real Capstone
+
+The bot project is too much to complete in this short amount of time, so instead I'm
+working with a
+[small dataset](https://archive-beta.ics.uci.edu/ml/datasets/auto+mpg)
+containing info about cars with some specs and I'll predict MPG. The problem itself for
+me is trivial from past study/experience as an auto mechanic so I should have a nice
+playground to focus completely on modeling. It's a very small data set too at < 400
+lines, I should be able to test multiple models in depth very quickly. It may or may not
+be interesting, expect a write-up anyway.
+
+### Cartman
+
+Well I guess I've adopted an 8 year old. Based on
+[this project](https://github.com/RuolinZheng08/twewy-discord-chatbot)
+I've trained a chat bot with the personality of Eric Cartman. He's a feature of my
+Discord bot living on a Raspberry Pi 4B, which I would say is probably the slowest
+computer you would ever want to run something like this on. It takes a somewhat
+reasonable amount of time to respond, almost feeling human if you make it think a bit.
+The project uses [PyTorch](https://pytorch.org/) to train the model. I'd like
+to re-create it using [TensorFlow](https://www.tensorflow.org/) as an
+exercise to understand each one better, but that's a project for another night. It also
+only responds to one line at a time so it can't carry a conversation with context,
+yet...
+
+### Website
+
+I never thought I'd end up having a blog. I had no plans at all actually when I set up
+this server, just to host a silly page that I would change from time to time whenever I
+was bored. I've been looking at
+[Hugo](https://gohugo.io/) as a way to organize what is now just a list of
+divs in a single html file slowly growing out of control. Basically you just dump each
+post into its own file, create a template of how to render them, and let it do its
+thing. I should be able to create a template that recreates exactly what you see right
+now, which is beginning to grow on me.
+
+If you haven't noticed yet, (and I don't blame you if you haven't because only a handful
+of people even visit this page) each time there is an update there is a completely new
+background image, color scheme, a whole new theme. This is because this page is a near
+identical representation of terminal windows open my computer and each time I update the
+page I also update it with my current wallpaper, which generates the color scheme
+dynamically using
+[Pywal](https://github.com/dylanaraps/pywal).
+
+TODO:
+* Code blocks with syntax highlighting
+* Develop an easy workflow to dump a jupyter notebook into the website and have it display nicely with minimal effort
+* Find a way to hack plots generated with matplotlib to change colors with the page color scheme (or find another way to do the same thing)
+* Automate generating the site - probably [Hugo](https://gohugo.io/)
+* Separate from blog, projects, etc.
+* Add socials, contact, about
+* A bunch of stuff I haven't even thought of yet
+
+That's all for now
diff --git a/dennis/test/bots/cartman.html b/dennis/test/bots/cartman.html
new file mode 100644
index 0000000..2755d2d
--- /dev/null
+++ b/dennis/test/bots/cartman.html
@@ -0,0 +1 @@
+cartman
diff --git a/dennis/test/filetest.py b/dennis/test/filetest.py
new file mode 100644
index 0000000..1924d99
--- /dev/null
+++ b/dennis/test/filetest.py
@@ -0,0 +1,49 @@
+import markdown
+from datetime import date, datetime
+import os
+from pydantic import BaseModel
+
+class Article(BaseModel):
+ content_type: str
+ title: str
+ date: date
+ content: str
+
+def walk_md(path: str):
+ buf = []
+
+ for root, _, files in os.walk(path):
+ mdeez = [f"{root}/{filename}" for filename in files if filename[-2:] == "md"]
+
+ if mdeez:
+ buf.extend(mdeez)
+
+ return buf
+
+def get_articles_from_root_dir(root_path: str) -> list[Article]:
+ md = markdown.Markdown(extensions=['meta'])
+ articles: list[Article] = []
+
+ for file_path in walk_md(root_path):
+ with open(file_path) as file:
+ html: str = md.convert(file.read());
+ meta: dict = md.Meta;
+
+ articles.append(
+ Article(
+ content_type=meta.get('content_type')[0],
+ title=meta.get('title')[0],
+ date=datetime.strptime( meta.get( 'date')[0], '%Y %m %d'),
+ content=html,
+ ));
+
+ return articles;
+
+DB = get_articles_from_root_dir('.');
+
+for article in DB:
+ print(
+ article.date,
+ article.content_type,
+ article.title,
+ )
diff --git a/dennis/test/games/adam.md b/dennis/test/games/adam.md
new file mode 100644
index 0000000..7cdb775
--- /dev/null
+++ b/dennis/test/games/adam.md
@@ -0,0 +1,6 @@
+Content_Type: game
+Title: adam
+Date: 2022 9 11
+
+[adam](https://old.doordesk.net/games/adam/) is a quick fps demo to test how well WebGL
+performs using [Unity](https://unity.com).
diff --git a/dennis/test/games/balls.md b/dennis/test/games/balls.md
new file mode 100644
index 0000000..6c6b9f2
--- /dev/null
+++ b/dennis/test/games/balls.md
@@ -0,0 +1,6 @@
+Content_Type: game
+Title: balls
+Date: 2022 9 13
+
+[balls](https://old.doordesk.net/games/balls/) is another demo to test WebGL performance.
+This time using [Godot Engine](https://godotengine.org/).
diff --git a/dennis/test/games/fps.md b/dennis/test/games/fps.md
new file mode 100644
index 0000000..11f045f
--- /dev/null
+++ b/dennis/test/games/fps.md
@@ -0,0 +1,6 @@
+Content_Type: game
+Title: fps
+Date: 2022 10 9
+
+[fps](https://old.doordesk.net/games/fps/) is a Godot/WebGL experiment from scratch with
+multiplayer using websockets and a master/slave architecture. Invite a friend or open multiple instances!
diff --git a/dennis/test/games/index.html b/dennis/test/games/index.html
new file mode 100644
index 0000000..68a671e
--- /dev/null
+++ b/dennis/test/games/index.html
@@ -0,0 +1,23 @@
+Some games using wasm/webgl
+Browser performance as of January 2023
+Tested better:
+
+ - Opera
+ - Firefox Developer Edition
+ - Brave
+
+Tested poor or broken:
+
+ - Safari
+ - Chrome stable release or older
+ - Edge, see above^
+
+Consider anything else average or let me know otherwise
+
+ ---MY GAMES---
+ - adam - The first. Unity Demo/Tutorial with some mods
+ - multiplayer fps - Dive into netcode with Godot (Open two, invite
+ your friends!)
+ - snek - Canvas + JS (the actual first)
+ - balls - Godot demo engine test
+
diff --git a/dennis/test/games/snek.md b/dennis/test/games/snek.md
new file mode 100644
index 0000000..c55fc4d
--- /dev/null
+++ b/dennis/test/games/snek.md
@@ -0,0 +1,5 @@
+Content_Type: game
+Title: snek
+Date: 2022 5 20
+
+[snek](https://old.doordesk.net/snek) is a simple snake game made with JS/Canvas.
diff --git a/dennis/test/projects/20220529-housing.md b/dennis/test/projects/20220529-housing.md
new file mode 100644
index 0000000..af80aac
--- /dev/null
+++ b/dennis/test/projects/20220529-housing.md
@@ -0,0 +1,112 @@
+Content_Type: project
+Title: Predicting Housing Prices
+Date: 2022 5 29
+
+A recent project I had for class was to use [scikit-learn](https://scikit-learn.org/stable/index.html) to create a regression model that will predict the price of a house based on some features of that house.
+
+### How?
+
+1 Pick out and analyze certain features from the dataset. Used here is the [Ames Iowa Housing Data](https://www.kaggle.com/datasets/marcopale/housing) set.
+1 Do some signal processing to provide a clearer input down the line, improving accuracy
+1 Make predictions on sale price
+1 Compare the predicted prices to recorded actual sale prices and score the results
+
+### What's important?
+
+Well, I don't know much about appraising houses. But I have heard the term "price per
+square foot" so we'll start with that:
+
+
+
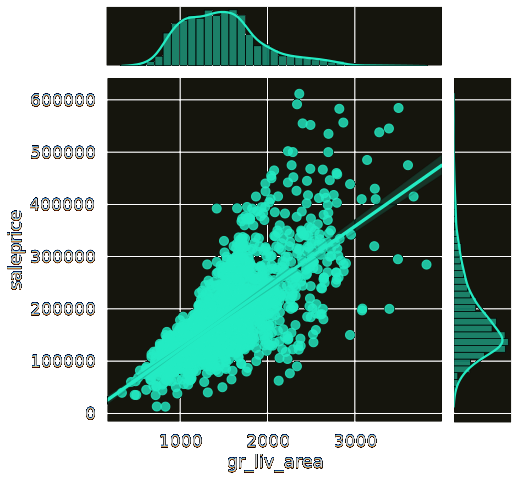
+There is a feature for 'Above Grade Living Area' meaning floor area that's not basement.
+It looks linear, there were a couple outliers to take care of but this should be a good
+signal.
+
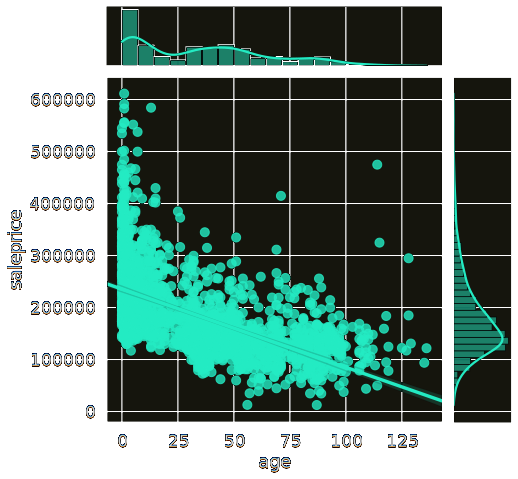
+Next I calculated the age of every house at time of sale and plotted it:
+
+
+
+Exactly what I'd expect to see. Price drops as age goes up, a few outliers. We'll
+include that in the model.
+
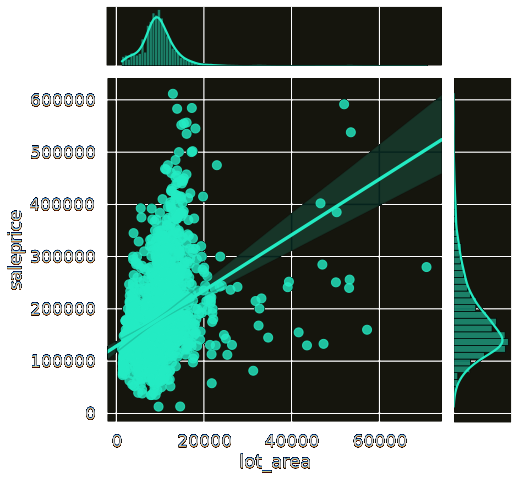
+Next I chose the area of the lot:
+
+
+
+Lot area positively affects sale price because land has value. Most of the houses here
+have similarly sized lots.
+
+### Pre-Processing
+
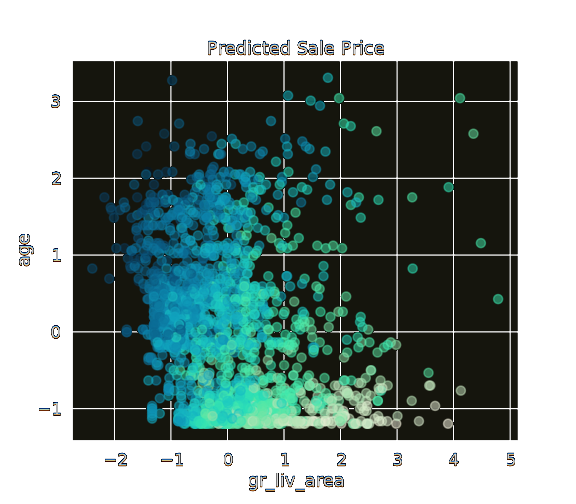
+
+ Here is an example where using
+ StandardScaler()
+ just doesn't cut it. The values are all scaled in a way where they can be compared
+ to one-another, but outliers have a huge effect on the clarity of the signal as a
+ whole.
+
+
+
+  +
+ 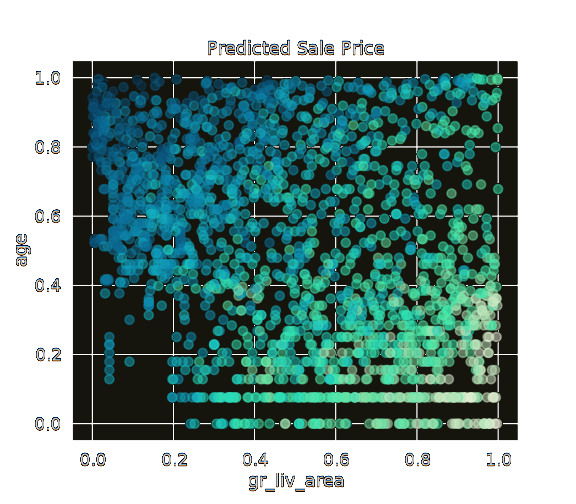 +
+
+
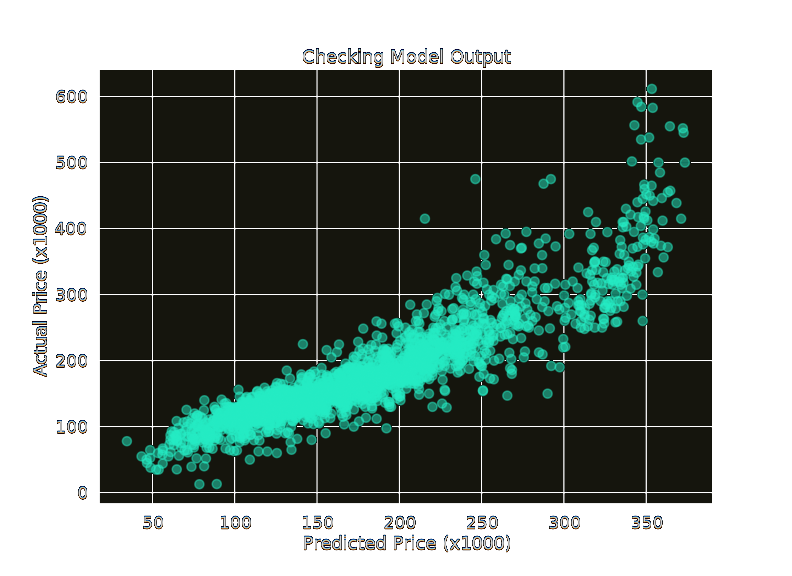 +
+
+Predictions were within about $35-$40k on average.
+
+It's a little fuzzy in the higher end of prices, I believe due to the small sample size.
+There are a few outliers that can probably be reduced with some deeper cleaning however
+I was worried about going too far and creating a different story. An "ideal" model in
+this case would look like a straight line.
+
+### Conclusion
+
+This model was designed with a focus on quality and consistency. With some refinement,
+the margin of error should be able to be reduced to a reasonable number and then
+reliable, accurate predictions can be made for any application where there is a need to
+assess the value of a property.
+
+I think a large limiting factor here is the size of the dataset compared to the quality
+of the features provided. There are
+more features
+from this dataset that can be included but I think the largest gains will be had from
+simply feeding in more data. As you stray from the "low hanging fruit" features, the
+quality of your model overall starts to go down.
+
+Here's an interesting case, Overall Condition of Property:
+
+
+
+
+
+Predictions were within about $35-$40k on average.
+
+It's a little fuzzy in the higher end of prices, I believe due to the small sample size.
+There are a few outliers that can probably be reduced with some deeper cleaning however
+I was worried about going too far and creating a different story. An "ideal" model in
+this case would look like a straight line.
+
+### Conclusion
+
+This model was designed with a focus on quality and consistency. With some refinement,
+the margin of error should be able to be reduced to a reasonable number and then
+reliable, accurate predictions can be made for any application where there is a need to
+assess the value of a property.
+
+I think a large limiting factor here is the size of the dataset compared to the quality
+of the features provided. There are
+more features
+from this dataset that can be included but I think the largest gains will be had from
+simply feeding in more data. As you stray from the "low hanging fruit" features, the
+quality of your model overall starts to go down.
+
+Here's an interesting case, Overall Condition of Property:
+
+
+  +
+
+You would expect sale price to increase with quality, no? Yet it goes down.. Why?
+
+I believe it's because a lot of sellers want to say that their house is of highest
+quality, no matter the condition. It seems that most normal people (who aren't liars)
+dont't care to rate their property and just say it's average. Both of these combined
+actually create a negative trend for quality which definitely won't help predictions!
+
+I would like to expand this in the future, maybe scraping websites like Zillow to gather
+more data.
+
+We'll see.
diff --git a/dennis/test/projects/20220614-reddit.md b/dennis/test/projects/20220614-reddit.md
new file mode 100644
index 0000000..586a9ed
--- /dev/null
+++ b/dennis/test/projects/20220614-reddit.md
@@ -0,0 +1,107 @@
+Content_Type: project
+Title: What goes into a successful Reddit post?
+Date: 2022 6 16
+
+In an attempt to find out what about a Reddit post makes it successful I will use some
+classification models to try to determine which features have the highest influence on
+making a correct prediction. In particular I use
+[Random Forest](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html)
+and
+[KNNeighbors](https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html)
+classifiers. Then I'll score the results and see what the highest predictors are.
+
+To find what goes into making a successful Reddit post we'll have to do a few things,
+first of which is collecting data:
+
+### Introducing Scrapey!
+
+[Scrapey](https://old.doordesk.net/projects/reddit/scrapey.html) is my scraper script that takes a snapshot
+of Reddit/r/all hot and saves the data to a .csv file including a calculated age for
+each post about every 12 minutes. Run time is about 2 minutes per iteration and each
+time adds about 100 unique posts to the list while updating any post it's already seen.
+
+I run this in the background in a terminal and it updates my data set every ~12 minutes.
+I have records of all posts within about 12 minutes of them disappearing from /r/all.
+
+### EDA
+
+[Next I take a quick look to see what looks useful](https://old.doordesk.net/projects/reddit/EDA.html), what
+doesn't, and check for outliers that will throw off the model. There were a few outliers
+to drop from the num_comments column.
+
+Chosen Features:
+
+* Title
+* Subreddit
+* Over_18
+* Is_Original_Content
+* Is_Self
+* Spoiler
+* Locked
+* Stickied
+* Num_Comments (Target)
+
+Then I split the data I'm going to use into two dataframes (numeric and non) to prepare
+for further processing.
+
+### Clean
+
+[Cleaning the data further](https://old.doordesk.net/projects/reddit/clean.html) consists of:
+
+* Scaling numeric features between 0-1
+* Converting '_' and '-' to whitespace
+* Removing any non a-z or A-Z or whitespace
+* Stripping any leftover whitespace
+* Deleting any titles that were reduced to empty strings
+
+### Model
+
+If the number of comments of a post is greater than the median total number of comments
+then it's assigned a 1, otherwise a 0. This is the target column. I then try some
+lemmatizing, it doesn't seem to add much. After that I create and join some dummies,
+then split and feed the new dataframe into
+[Random Forest](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html)
+and [NNeighbors](https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html)
+classifiers. Both actually scored the same with
+[cross validation](https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_validate.html)
+so I mainly used the forest.
+
+[Notebook Here](https://old.doordesk.net/projects/reddit/model.html)
+
+### Conclusion
+
+Some Predictors from Top 25:
+
+* Is_Self
+* Subreddit_Memes
+* OC
+* Over_18
+* Subreddit_Shitposting
+* Is_Original_Content
+* Subreddit_Superstonk
+
+ Popular words: 'like', 'just', 'time', 'new', 'oc', 'good', 'got', 'day', 'today', 'im',
+ 'dont', and 'love'.
+
+ People on Reddit (at least in the past few days) like their memes, porn, and talking
+ about their day. And it's preferred if the content is original and self posted. So yes,
+ post your memes to memes and shitposting, tag them NSFW, use some words from the list,
+ and rake in all that sweet karma!
+
+ But it's not that simple, this is a fairly simple model, with simple data. To go beyond
+ this I think the comments would have to be analyzed.
+ [Lemmatisation](https://en.wikipedia.org/wiki/Lemmatisation) I thought would
+ be the most influential piece, and I still think that thinking is correct. But in this
+ case it doesn't apply because there is no real meaning to be had from reddit post
+ titles, at least to a computer. (or I did something wrong)
+
+ There's a lot more seen by a human than just the text in the title, there's often an
+ image attached, most posts reference a recent/current event, they could be an inside
+ joke of sorts. For some posts there could be emojis in the title, and depending on their
+ combination they can take on a meaning completely different from their individual
+ meanings. The next step from here I believe is to analyze the comments section of these
+ posts because in this moment I think that's the easiest way to truly describe the
+ meaning of a post to a computer. With what was gathered here I'm only to get 10% above
+ baseline and I think that's all there is to be had here, I mean we can tweak for a few
+ percent probably but I don't think there's much left on the table.
+
diff --git a/dennis/test/projects/20221020-cartman.md b/dennis/test/projects/20221020-cartman.md
new file mode 100644
index 0000000..ca124ca
--- /dev/null
+++ b/dennis/test/projects/20221020-cartman.md
@@ -0,0 +1,30 @@
+Content_Type: project
+Title: Cartman is public!
+Date: 2022 10 20
+
+[Cartman](https://old.doordesk.net/cartman) is trained by combining Microsoft's
+[DialoGPT-medium](https://huggingface.co/microsoft/DialoGPT-medium)
+NLP model (GPT2 model trained on 147M samples of multi-turn dialogue from Reddit) with 17 seasons of
+[South Park](https://southparkstudios.com)
+transcripts.
+
+Requests are routed from
+[Nginx](https://nginx.com)
+through
+[WireGuard](https://www.wireguard.com)
+to a
+[Raspberry Pi 4B 8GB](https://www.tomshardware.com/news/raspberry-pi-4-8gb-tested) running
+[FastAPI](https://fastapi.tiangolo.com),
+and the Cartman model using [PyTorch](https://pytorch.org).
+It has enough RAM for more, but the CPU is pretty much at its limit. Expect it to take a few
+seconds, I'm cheap. Sorry(kinda).
+
+You can download a Docker image if you'd like to run it on your own hardware for either
+[x86_64](https://old.doordesk.net/files/chatbots_api_x86_64.tar.gz)
+or
+[aarch64](https://old.doordesk.net/files/chatbots_api_aarch64.tar.gz).
+
+More info [here](https://github.com/adoyle0/cartman) as well as
+[example scripts](https://github.com/adoyle0/cartman/tree/master/api/test)
+to talk to the docker container.
+
diff --git a/dennis/test/projects/20230427-lightning.md b/dennis/test/projects/20230427-lightning.md
new file mode 100644
index 0000000..bc9b114
--- /dev/null
+++ b/dennis/test/projects/20230427-lightning.md
@@ -0,0 +1,10 @@
+Content_Type: project
+Title: Lightning
+Date: 2023 4 27
+
+[Lightning](https://lightning.doordesk.net) is a mapping/data vis project for finding
+EV charging stations. It uses [Martin](https://github.com/maplibre/martin) to serve
+tiles generated from [OpenStreetMap](https://www.openstreetmap.org) data to a
+ [MapLibre](https://maplibre.org/) frontend. Additional layers are added on top
+via [Deck.gl](https://deck.gl) using data from [EVChargerFinder](https://github.com/kevin-fwu/EVChargerFinder) made by my friend
+Kevin.
diff --git a/dennis/test/runtest b/dennis/test/runtest
new file mode 100755
index 0000000..4ab7b1e
--- /dev/null
+++ b/dennis/test/runtest
@@ -0,0 +1,4 @@
+#!/bin/bash
+
+clear &&
+python filetest.py
+
+
+You would expect sale price to increase with quality, no? Yet it goes down.. Why?
+
+I believe it's because a lot of sellers want to say that their house is of highest
+quality, no matter the condition. It seems that most normal people (who aren't liars)
+dont't care to rate their property and just say it's average. Both of these combined
+actually create a negative trend for quality which definitely won't help predictions!
+
+I would like to expand this in the future, maybe scraping websites like Zillow to gather
+more data.
+
+We'll see.
diff --git a/dennis/test/projects/20220614-reddit.md b/dennis/test/projects/20220614-reddit.md
new file mode 100644
index 0000000..586a9ed
--- /dev/null
+++ b/dennis/test/projects/20220614-reddit.md
@@ -0,0 +1,107 @@
+Content_Type: project
+Title: What goes into a successful Reddit post?
+Date: 2022 6 16
+
+In an attempt to find out what about a Reddit post makes it successful I will use some
+classification models to try to determine which features have the highest influence on
+making a correct prediction. In particular I use
+[Random Forest](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html)
+and
+[KNNeighbors](https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html)
+classifiers. Then I'll score the results and see what the highest predictors are.
+
+To find what goes into making a successful Reddit post we'll have to do a few things,
+first of which is collecting data:
+
+### Introducing Scrapey!
+
+[Scrapey](https://old.doordesk.net/projects/reddit/scrapey.html) is my scraper script that takes a snapshot
+of Reddit/r/all hot and saves the data to a .csv file including a calculated age for
+each post about every 12 minutes. Run time is about 2 minutes per iteration and each
+time adds about 100 unique posts to the list while updating any post it's already seen.
+
+I run this in the background in a terminal and it updates my data set every ~12 minutes.
+I have records of all posts within about 12 minutes of them disappearing from /r/all.
+
+### EDA
+
+[Next I take a quick look to see what looks useful](https://old.doordesk.net/projects/reddit/EDA.html), what
+doesn't, and check for outliers that will throw off the model. There were a few outliers
+to drop from the num_comments column.
+
+Chosen Features:
+
+* Title
+* Subreddit
+* Over_18
+* Is_Original_Content
+* Is_Self
+* Spoiler
+* Locked
+* Stickied
+* Num_Comments (Target)
+
+Then I split the data I'm going to use into two dataframes (numeric and non) to prepare
+for further processing.
+
+### Clean
+
+[Cleaning the data further](https://old.doordesk.net/projects/reddit/clean.html) consists of:
+
+* Scaling numeric features between 0-1
+* Converting '_' and '-' to whitespace
+* Removing any non a-z or A-Z or whitespace
+* Stripping any leftover whitespace
+* Deleting any titles that were reduced to empty strings
+
+### Model
+
+If the number of comments of a post is greater than the median total number of comments
+then it's assigned a 1, otherwise a 0. This is the target column. I then try some
+lemmatizing, it doesn't seem to add much. After that I create and join some dummies,
+then split and feed the new dataframe into
+[Random Forest](https://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html)
+and [NNeighbors](https://scikit-learn.org/stable/modules/generated/sklearn.neighbors.KNeighborsClassifier.html)
+classifiers. Both actually scored the same with
+[cross validation](https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_validate.html)
+so I mainly used the forest.
+
+[Notebook Here](https://old.doordesk.net/projects/reddit/model.html)
+
+### Conclusion
+
+Some Predictors from Top 25:
+
+* Is_Self
+* Subreddit_Memes
+* OC
+* Over_18
+* Subreddit_Shitposting
+* Is_Original_Content
+* Subreddit_Superstonk
+
+ Popular words: 'like', 'just', 'time', 'new', 'oc', 'good', 'got', 'day', 'today', 'im',
+ 'dont', and 'love'.
+
+ People on Reddit (at least in the past few days) like their memes, porn, and talking
+ about their day. And it's preferred if the content is original and self posted. So yes,
+ post your memes to memes and shitposting, tag them NSFW, use some words from the list,
+ and rake in all that sweet karma!
+
+ But it's not that simple, this is a fairly simple model, with simple data. To go beyond
+ this I think the comments would have to be analyzed.
+ [Lemmatisation](https://en.wikipedia.org/wiki/Lemmatisation) I thought would
+ be the most influential piece, and I still think that thinking is correct. But in this
+ case it doesn't apply because there is no real meaning to be had from reddit post
+ titles, at least to a computer. (or I did something wrong)
+
+ There's a lot more seen by a human than just the text in the title, there's often an
+ image attached, most posts reference a recent/current event, they could be an inside
+ joke of sorts. For some posts there could be emojis in the title, and depending on their
+ combination they can take on a meaning completely different from their individual
+ meanings. The next step from here I believe is to analyze the comments section of these
+ posts because in this moment I think that's the easiest way to truly describe the
+ meaning of a post to a computer. With what was gathered here I'm only to get 10% above
+ baseline and I think that's all there is to be had here, I mean we can tweak for a few
+ percent probably but I don't think there's much left on the table.
+
diff --git a/dennis/test/projects/20221020-cartman.md b/dennis/test/projects/20221020-cartman.md
new file mode 100644
index 0000000..ca124ca
--- /dev/null
+++ b/dennis/test/projects/20221020-cartman.md
@@ -0,0 +1,30 @@
+Content_Type: project
+Title: Cartman is public!
+Date: 2022 10 20
+
+[Cartman](https://old.doordesk.net/cartman) is trained by combining Microsoft's
+[DialoGPT-medium](https://huggingface.co/microsoft/DialoGPT-medium)
+NLP model (GPT2 model trained on 147M samples of multi-turn dialogue from Reddit) with 17 seasons of
+[South Park](https://southparkstudios.com)
+transcripts.
+
+Requests are routed from
+[Nginx](https://nginx.com)
+through
+[WireGuard](https://www.wireguard.com)
+to a
+[Raspberry Pi 4B 8GB](https://www.tomshardware.com/news/raspberry-pi-4-8gb-tested) running
+[FastAPI](https://fastapi.tiangolo.com),
+and the Cartman model using [PyTorch](https://pytorch.org).
+It has enough RAM for more, but the CPU is pretty much at its limit. Expect it to take a few
+seconds, I'm cheap. Sorry(kinda).
+
+You can download a Docker image if you'd like to run it on your own hardware for either
+[x86_64](https://old.doordesk.net/files/chatbots_api_x86_64.tar.gz)
+or
+[aarch64](https://old.doordesk.net/files/chatbots_api_aarch64.tar.gz).
+
+More info [here](https://github.com/adoyle0/cartman) as well as
+[example scripts](https://github.com/adoyle0/cartman/tree/master/api/test)
+to talk to the docker container.
+
diff --git a/dennis/test/projects/20230427-lightning.md b/dennis/test/projects/20230427-lightning.md
new file mode 100644
index 0000000..bc9b114
--- /dev/null
+++ b/dennis/test/projects/20230427-lightning.md
@@ -0,0 +1,10 @@
+Content_Type: project
+Title: Lightning
+Date: 2023 4 27
+
+[Lightning](https://lightning.doordesk.net) is a mapping/data vis project for finding
+EV charging stations. It uses [Martin](https://github.com/maplibre/martin) to serve
+tiles generated from [OpenStreetMap](https://www.openstreetmap.org) data to a
+ [MapLibre](https://maplibre.org/) frontend. Additional layers are added on top
+via [Deck.gl](https://deck.gl) using data from [EVChargerFinder](https://github.com/kevin-fwu/EVChargerFinder) made by my friend
+Kevin.
diff --git a/dennis/test/runtest b/dennis/test/runtest
new file mode 100755
index 0000000..4ab7b1e
--- /dev/null
+++ b/dennis/test/runtest
@@ -0,0 +1,4 @@
+#!/bin/bash
+
+clear &&
+python filetest.py