4.7 KiB
content_type = "project"
title = "Predicting Housing Prices"
date = "2022 05 29"
A recent project I had for class was to use scikit-learn to create a regression model that will predict the price of a house based on some features of that house.
How?
1 Pick out and analyze certain features from the dataset. Used here is the Ames Iowa Housing Data set. 1 Do some signal processing to provide a clearer input down the line, improving accuracy 1 Make predictions on sale price 1 Compare the predicted prices to recorded actual sale prices and score the results
What's important?
Well, I don't know much about appraising houses. But I have heard the term "price per square foot" so we'll start with that:
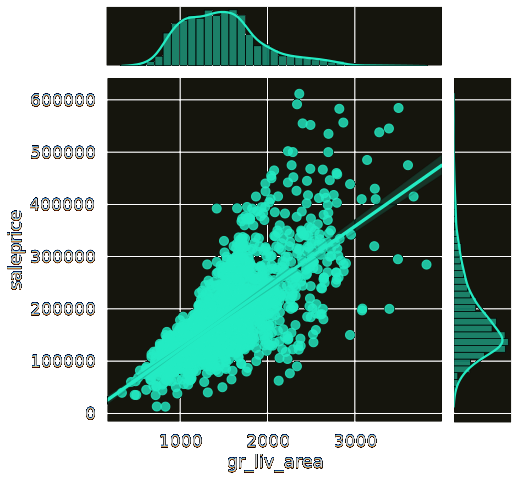
There is a feature for 'Above Grade Living Area' meaning floor area that's not basement. It looks linear, there were a couple outliers to take care of but this should be a good signal.
Next I calculated the age of every house at time of sale and plotted it:
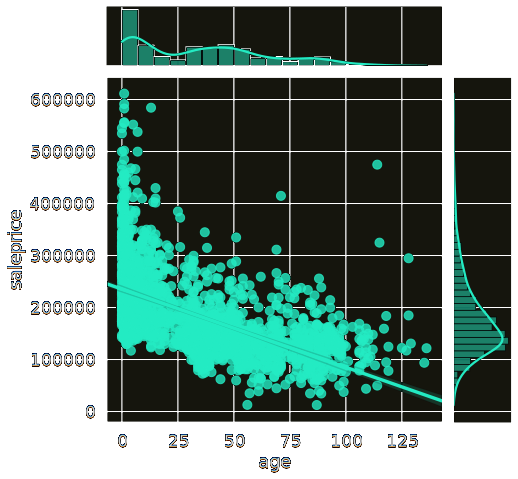
Exactly what I'd expect to see. Price drops as age goes up, a few outliers. We'll include that in the model.
Next I chose the area of the lot:
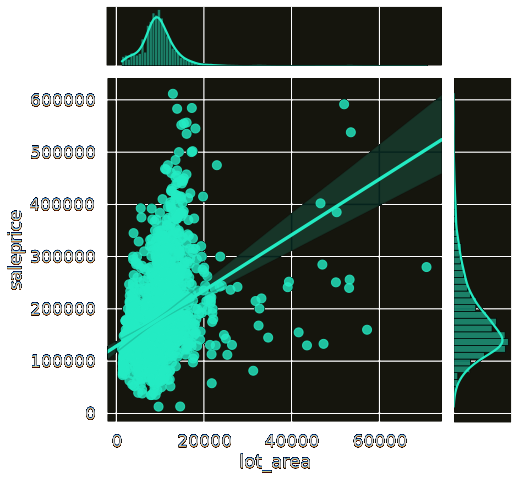
Lot area positively affects sale price because land has value. Most of the houses here have similarly sized lots.
Pre-Processing
Here is an example where using StandardScaler() just doesn't cut it. The values are all scaled in a way where they can be compared to one-another, but outliers have a huge effect on the clarity of the signal as a whole.
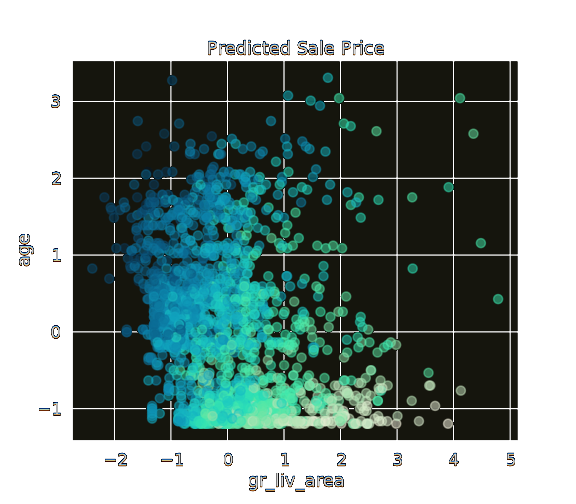
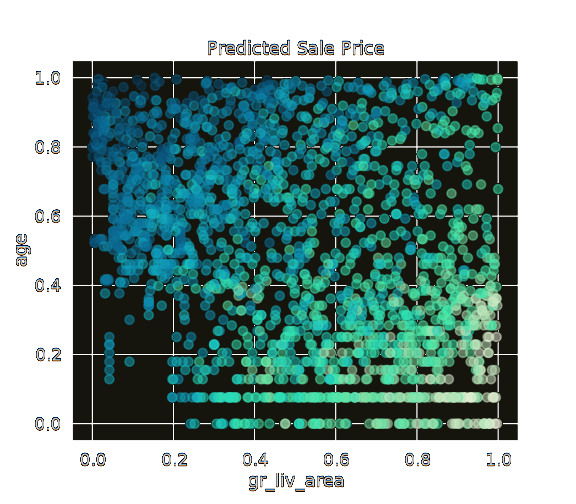
You should clearly see in the second figure that an old shed represented in the top left corner will sell for far less than a brand new mansion represented in the bottom right corner. This is the result of using the QuantileTransformer() for scaling.
The Model
A simple LinearRegression() should do just fine, with QuantileTransformer() scaling of course.
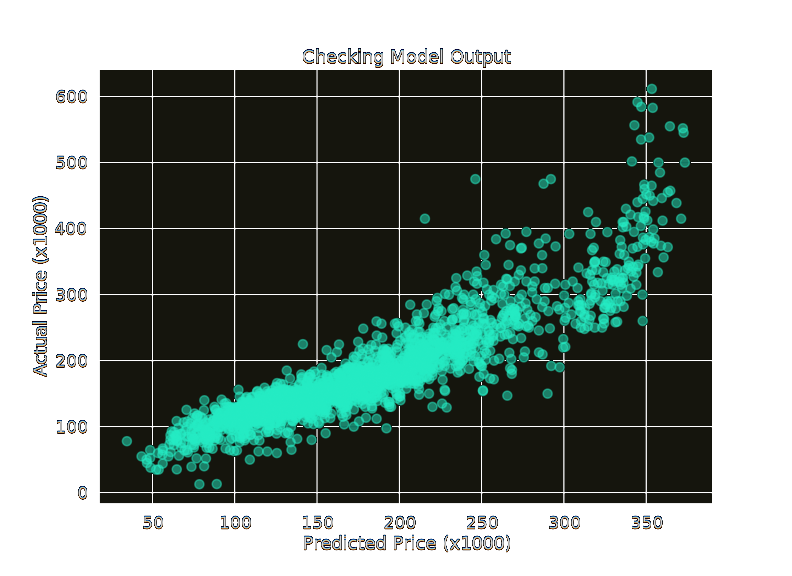
Predictions were within about $35-$40k on average.
It's a little fuzzy in the higher end of prices, I believe due to the small sample size. There are a few outliers that can probably be reduced with some deeper cleaning however I was worried about going too far and creating a different story. An "ideal" model in this case would look like a straight line.
Conclusion
This model was designed with a focus on quality and consistency. With some refinement, the margin of error should be able to be reduced to a reasonable number and then reliable, accurate predictions can be made for any application where there is a need to assess the value of a property.
I think a large limiting factor here is the size of the dataset compared to the quality of the features provided. There are more features from this dataset that can be included but I think the largest gains will be had from simply feeding in more data. As you stray from the "low hanging fruit" features, the quality of your model overall starts to go down.
Here's an interesting case, Overall Condition of Property:

You would expect sale price to increase with quality, no? Yet it goes down.. Why?
I believe it's because a lot of sellers want to say that their house is of highest quality, no matter the condition. It seems that most normal people (who aren't liars) dont't care to rate their property and just say it's average. Both of these combined actually create a negative trend for quality which definitely won't help predictions!
I would like to expand this in the future, maybe scraping websites like Zillow to gather more data.
We'll see.